Input Data Settings
Overview
AnyChart Stock gets data in the CSV format, so configuring the CSV settings properly is something you must carefully observe and double-check.
The component's engine cannot figure out which exactly format is used in the CSV table, so it is your responsibility to make the CSV table settings and timestamp format in a way that the component would be able to parse the input data.
A CSV table can come from a third-party server-side script, Web-Service or file, and sometimes developer cannot modify the format of that table (or that may be a challenging task). For such cases, AnyChart Stock has a lot of options that enable it to use CSV tables with just about any possible formatting.
As you should already know from the AnyChart Data Model, a CSV table is wrapped with a Data Set, which knows where the table comes from. When specifying the data source value in the Data Set, you should also specify how the source table is formatted.
There are two major nodes that define source CSV table format:
- <csv_settings> - here you can configure column and row separators and other CSV format-related settings.
- <locale> - here you define timestamp column format, time offset (if any), and value column number format.
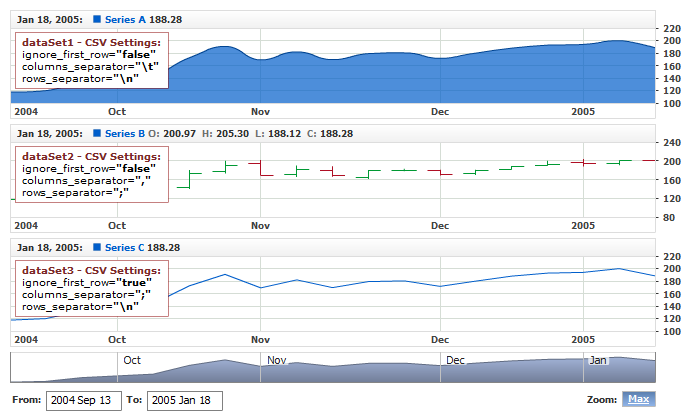
Here is a sample XML that shows two Data Sets with different locale and CSV settings:
01 |
<?xml version="1.0" encoding="UTF-8"?> |
02 |
<stock xmlns="http://anychart.com/products/stock/schemas/1.9.0/schema.xsd"> |

CSV Settings and CSV Table Requirements
The CSV parser in AnyChart Stock supports Comma Separated Values format specifications, and some of the CSV parameters are configurable.
If you need to learn more about the CSV format, this article is a good starting point:
CSV Table Requirements
First of all, the nature of the component requires the CSV table to have at least two columns: one with timestamps and the other (others) with values.
General requirements are:
- Columns headers - the first row may contain row headers; if it is so - that fact should be declared in the CSV settings.
- Commas in timestamps - if a timestamp contains commas (","), and comma is used as the column separator - the timestamp should be put in double quotes; for example, "28 May, 2010". If you omit the double quotes, you should change the column separator to semicolon (";") or something else.
- Commas in values - if the values in the value columns use commas as the decimal or thousands separator, and comma is used as the column separator - the values should be put in double quotes; for example, "1,092,432". If you omit the double quotes, you should change the column separator to semicolon (";") or something else.
- Values format - values in the value columns may contain either the values in standart decimal format with '0','1','2','3','4','5','6','7','8','9' characters and the decimal and thousand separator characters or numbers in exponential format (like 100.2e10). By default, the decimal separator is dot ("."), and there is no thousand separator. You can redefine those characters, please see the Numbers Format section to learn more.
- Missing values - the value column should be empty in order to be treated as "missing" by the component.
CSV Parser Settings
As it has been said already, some CSV table settings can be customized; if the CSV tables you use don't fit the default settings, you can alter the parser settings, so that it could read the data properly.
The <csv_settings> node has the following attributes:
| Attribute |
Default |
Description |
| ignore_first_row (!) |
"false" |
Sets whether the parser should ignore the first row of data. It may be useful when the first row contains column descriptions. Can be true or false. |
| rows_separator (!) |
"\r\n" |
Sets the string that separates rows in the CSV data set. The most common separators are new line (LF) - "\n", new line and carriage return (CR LF) - "\r\n" and carriage return (CR) "\r".
The component also recognizes these special separator characters: "\n", "\r" and "\t".
To use the backslash "\" as a part of the separator, escape it by typing the double backslash: "\\". Other characters after the "\" character are used as they are, and the "\" character is replaced and ignored. |
| columns_separator (!) |
"," |
Sets a string that separates columns in a CSV data set. The most common separators are ";" and ",".
The component also recognizes these special separator characters: "\n", "\r" and "\t". To use the backslash "\" as a part of the separator, escape it by typing the double backslash: "\\". Other characters after the "\" character are used as they are, and the "\" character is replaced and ignored. |
| ignore_trailing_spaces |
"false" |
Sets whether the CSV parser should trim the space characters from both sides of the parsed values. Can be true or false. |
Note: We have marked the three out of four attributes with (!) because misunderstanding and misusing those can become a real pain in the neck and turn the process of creating a simple chart into hell. Please consider the following recommendations:
1) Check the first row of the CSV table - does it contain column headers?
- If it does and contains something like "Date,Open,High,Low,Close,Volume" - exclude this row from the data set by setting the ignore_first_row setting to true. Failing to do that could cause parsing the results the wrong way.
- If there is no header row - make sure that the ignore_first_row setting is NOT set to true; otherwise, you will always be losing the first row of data! Set ignore_first_row to false explicitly or simply remove it from the settings.
2) If the columns are separated with a character other than comma - define it using the columns_separator attribute; for example, <csv_settings columns_separator="\t">.
3) If the rows are separated with a character other than carriage return and line feed ("\r\n") - define it using the rows_separator attribute; for example, <csv_settings rows_separator=";"/>.
The sample XML below shows how the CSV settings can be altered:
08 |
<csv_data><![CDATA[Date;Open;High;Low;Close;Volume |
09 |
1971-02-05;100;100;100;100;0 |
10 |
1971-02-08;100.84;100.84;100.84;100.84;0 |
11 |
1971-02-09;100.76;100.76;100.76;100.76;0 |
12 |
1971-02-10;100.69;100.69;100.69;100.69;0 |
13 |
1971-02-11;101.45;101.45;101.45;101.45;0 |
14 |
1971-02-12;102.05;102.05;102.05;102.05;0 |
15 |
1971-02-16;102.19;102.19;102.19;102.19;0 |
16 |
1971-02-17;101.74;101.74;101.74;101.74;0 |
17 |
1971-02-18;101.42;101.42;101.42;101.42;0]]></csv_data> |
15 | csvData: "Date;Open;High;Low;Close;Volume\r\n1971-02-05;100;100;100;100;0\r\n1971-02-08;100.84;100.84;100.84;100.84;0\r\n1971-02-09;100.76;100.76;100.76;100.76;0\r\n1971-02-10;100.69;100.69;100.69;100.69;0\r\n1971-02-11;101.45;101.45;101.45;101.45;0\r\n1971-02-12;102.05;102.05;102.05;102.05;0\r\n1971-02-16;102.19;102.19;102.19;102.19;0\r\n1971-02-17;101.74;101.74;101.74;101.74;0\r\n1971-02-18;101.42;101.42;101.42;101.42;0" |
The live sample below uses several data sets that use CSV tables formatted different ways:
Live Sample: Input Data - CSV Parsing Settings
Using Non-Latin and Special Symbols
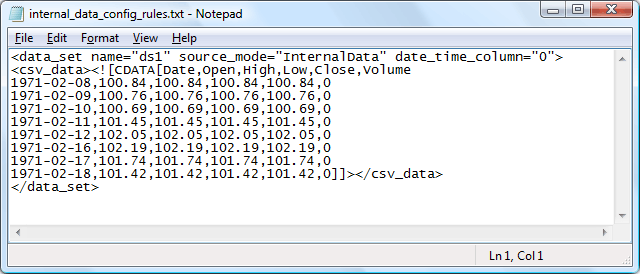
When you use non-latin symbols in CSV files you need to make sure your file (or script output) is UTF-8 encoded.
If you are using internal data sets you should not only make sure XML file is UTF-8 encoded, but also:
- Put CSV table in <![CDATA[]]>.
- Opening "<![CDATA[ " comes right after "<csv_data>" and there is no spaces, tabs, line breaks or other symbols between them.
- The first row starts right after "<![CDATA[ " there is no spaces, tabs, line breaks or other symbols between them.
- Each row starts from the beginning of the line and there is no spaces, tabs, line breaks or other symbols before the first column.
- The last row ends with "]]></csv_data>" after the last column.
If you would not follow the rules listed above - in some browser CSV table may be parsed incorrectly. The screen shot below shows the sample internal data set formatted properly:
Timestamps
AnyChart Stock can accept and visualize date and time data at up to a millisecond precision. Every data set must contain the timestamp column, and its date-time format must be specified.
Timestamp format
The timestamp format string is set in the <format> node. This format string uses special tokens. The sample XML below demonstrates it. For better understanding, we will use an internal CSV table:
10 | csvData: "Date,Value\r\n1971-02-05,100.00\r\n1971-02-08,100.84\r\n1971-02-09,100.76" |
As you can see here, the CSV table contains daily data with timestamps that appear as: 1971-02-05, 1971-10-23, etc. Here, years are represented by four digits, months and days - by two with leading zeros, and all the units are separated with the "-" character.
To help AnyChart Stock properly interpret this timestamp, we will specify the following input format string: "%yyyy-%MM-%dd", where the tokens have the following meanings:
- %yyyy - stands for four-digit year: 1991, 2002, 2010, etc.
- %MM - stands for month number from 1 to 12 with leading zeros, which means that the values lesser than 10 should begin with a zero: 01,05,07, etc.
- %dd - stands for date (day number) from 1 to 31 with leading zeros as well: 03, 07, 09, etc.
And the "-" character, used as the separator, is also included in the proper positions of the format string.
There are no restrictions on using timestamp formats - you can use any; just make sure to specify the formatting string properly and that all the values in the timestamp column satisfy that string.
Take a look at the table below; it highlights the case which should never happen with the timestamp column:
| Correct |
Wrong! |
|
1990-03-26
1990-04-02
1990-04-09
1990-04-16
1990-04-23 |
1990-03-26
1990-04-02
1990/4/9
1990-04-16
1990-04-23 |
As we have already said, you can use any format - with any separators, prefixes and suffixes. The table below demonstrates several different formatting strings, which use the same tokens %yyyy, %MM and %dd arranged in different ways:
| Description |
Timestamps |
Timestamp format string |
| Year, month, day with the "-" separator. |
1990-03-26
1990-04-02
1990-04-09
1990-04-16
1990-04-23
|
"%yyyy-%MM-%dd" |
| Year, month, day with leading zeros can be used without separators. |
19900326
19900402
19900409
19900416
19900423 |
"%yyyy%MM%dd" |
| Month, day, year with the "/" separator. |
03/26/1990
04/02/1990
04/09/1990
04/16/1990
04/23/1990 |
"%MM/%dd/%yyyy" |
Year, month, day with prefixes and the comma (",") separator.
Note: As stated in the requirements, if a timestamp contains a comma, and the column separator is comma (default) - the timestamp should be typed in double quotes. |
"Y:1990,M:03,D:26"
"Y:1990,M:04,D:02"
"Y:1990,M:04,D:09"
"Y:1990,M:04,D:16"
"Y:1990,M:04,D:23"
|
"Y:%yyyy,M:%MM,D:%dd" |
This table has demonstrated an example of basic formatting; depending on the task, you can use any format and apply the hour, minute, second or milliseconds precision.
The section below shows all the tokens that can be used in a timestamp formatting string.
Tokens for Date-Time Format
AnyChart Stock's timestamp formatting string can be divided in two categories: complex and standard:
- Standard - these are the tokens that parse date time provided in some standardized format; for example, Unix Timestamp. When using such tokens, you just need to set one token; for example, <format>%u</format>.
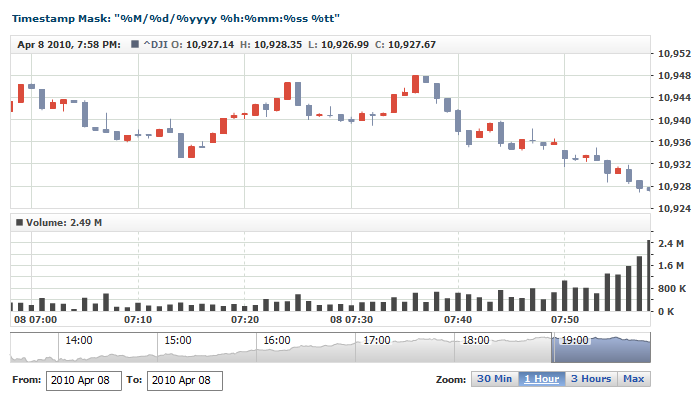
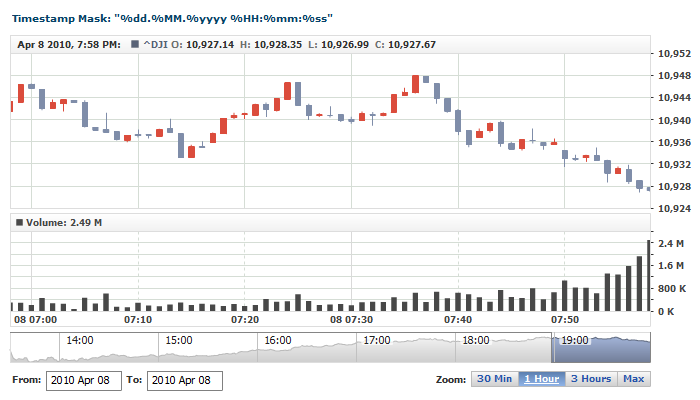
- Complex String - these are the format strings that consist of several tokens. Such strings are used when input data comes in a complex format; for example, to parse "27 January, 2009 3:12:45.456 PM" - you would need to use this formatting string: "%dd %MMMM, %yyyy %h:%mm:%ss.%fff %tt"
The table below lists all the available tokens that can be used in a formatting string that parses input timestamp. The Examples column shows sample timestamps and the formatting strings used for parsing them:
| Token |
Description |
Examples |
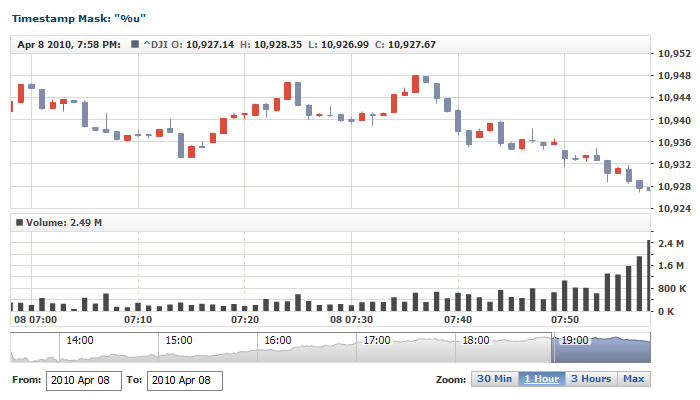
| %u |
Expects the number of Seconds elapsed since midnight of January 1, 1970.
Should follow the Unix Timestamp format.
When using this token, no other tokens can be used in the mask, and the timestamp can contain only one numerical value. |
Timestamp: "1269675274"
Mask: "%u" |
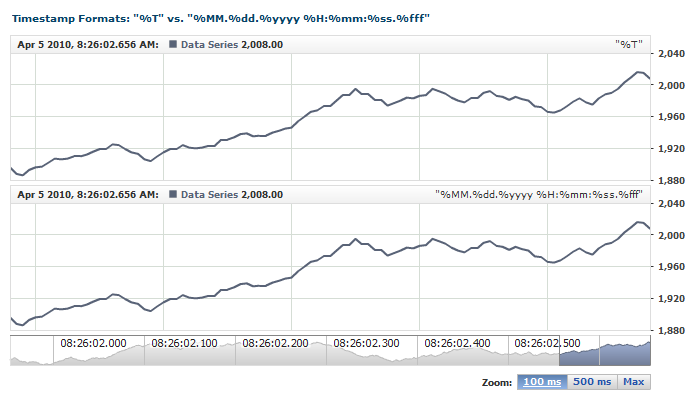
| %T |
Expects the number of Milliseconds since midnight of January 1, 1970
When using this token, no other tokens can be used in the mask, and the timestamp can contain only one numerical value. |
Timestamp: "1269675350168"
Mask: "%T" |
| %d |
Expects day of month as a number from 1 through 31.
Single-digit days must be formatted without a leading zero.
Note: Must be followed by a non-digit character - read more... |
Timestamp: "6/9/2009"
Mask: "%M/%d/%yyyy" |
| %dd |
Expects day of month as a number from 01 through 31.
Single-digit days must be formatted with a leading zero. |
Timestamp: "06/09/2009"
Mask: "%MM/%dd/%yyyy" |
| %ddd |
Expects short weekday name.
The name must match the locale settings and doesn't affect the result - read more... |
Timestamp: "06-Sep-2009"
Mask: "%MM-%ddd-%yyyy" |
| %dddd |
Expects full weekday name.
The name should match the locale settings and doesn't affect the result - read more... |
Timestamp: "06-September-2009"
Mask: "%MM-%dddd-%yyyy" |
| %M |
Expects month as a number from 1 through 12.
Single-digit months must be formatted without a leading zero.
Note: Must be followed by a non-digit character - read more... |
Timestamp: "6/23/2009"
Mask: "%M/%d/%yyyy" |
| %MM |
Expects month as a number from 01 through 12.
Single-digit months must be formatted with a leading zero. |
Timestamp: "06/09/2009"
Mask: "%MM/%dd/%yyyy" |
| %MMM |
Expects abbreviated month name.
The name should match the locale settings - read more... |
Timestamp: 25 Feb, 2009"
Mask: "%d %MMM, %yyyy" |
| %MMMM |
Expects full month name.
The name should match the locale settings - read more... |
Timestamp: "25 February, 2009"
Mask: "%d %MMMM, %yyyy" |
| %yy |
Expects year as a two-digit number.
If the year has more than two digits, only the two lower-order digits will appear. If a two-digit year has fewer than two value digits, the number must be padded with leading zeros until obtaining two digits. |
Timestamp: "2/25/09"
Mask: "%M/%d/%yy" |
| %yyyy |
Expects year as a four-digit number. |
Timestamp: "2/25/2009"
Mask: "%M/%d/%yyyy" |
| %h |
Expects hour as a number from 1 through 12.
The hour is represented by the 12-hour clock, which counts whole hours since midnight or noon. A particular hour after midnight is indistinguishable from the same hour after noon. The hour is not rounded, and single-digit hours are formatted without a leading zero. For example, given the time of 4:12 in the morning or afternoon, this custom format specifier expects "4".
Note: Must be followed by a non-digit character - read more... |
Timestamp: "2/25/2009 3:15 PM"
Mask: "%M/%d/%yyyy %h:%mm %tt" |
| %hh |
Expects hour as a number from 01 through 12.
The hour is represented by the 12-hour clock that counts whole hours since midnight or noon. A particular hour after midnight is indistinguishable from the same hour after noon. The hour is not rounded, and single-digit hours are formatted with a leading zero. For example, given the time of 4:12 in the morning or afternoon, this format specifier expects "04". |
Timestamp: "2/25/2009 03:15 PM"
Mask: "%M/%d/%yyyy %hh:%mm %tt" |
| %H |
Expects hour as a number from 0 through 23.
The hour is represented by the zero-based 24-hour clock that counts whole hours since midnight. Single-digit hours must be formatted without a leading zero.
Note: Must be followed by a non-digit character - read more... |
Timestamp: "2/25/2009 17:15"
Mask: "%M/%d/%yyyy %H:%mm %tt" |
| %HH |
Expects hour as a number from 00 through 23.
The hour is represented by the zero-based 24-hour clock that counts whole hours since midnight. Single-digit hours must be formatted with a leading zero. |
Timestamp: "2/25/2009 17:15"
Mask: "%M/%d/%yyyy %HH:%mm %tt" |
| %m |
Expects minute as a number from 0 through 59.
The value represents the number of whole minutes passed since the last hour. Single-digit minute s must be formatted without a leading zero.
Note: Must be followed by a non-digit character - read more... |
Timestamp: "2/25/2009 3:15 PM"
Mask: "%M/%d/%yyyy %h:%m %tt" |
| %mm |
Expects minute as a number from 00 through 59.
The value represents the number of whole minutes passed since the last hour. Single-digit minutes must be formatted with a leading zero. |
Timestamp: "2/25/2009 3:15 PM"
Mask: "%M/%d/%yyyy %h:%mm %tt" |
| %s |
Expects seconds as a number from 0 through 59.
The value represents the number of whole seconds passed since the last minute. Single-digit seconds must be formatted without a leading zero.
Note: Must be followed by a non-digit character - read more... |
Timestamp: "2/25/2009 17:15:23"
Mask: "%M/%d/%yyyy %H:%mm:%s" |
| %ss |
Expects seconds as a number from 00 through 59.
The value represents the number of whole seconds passed since the last minute. Single-digit seconds must be formatted with a leading zero. |
Timestamp: "2/25/2009 17:15:03"
Mask: "%M/%d/%yyyy %H:%mm:%ss" |
| %f |
Expects the most significant digit of the seconds fraction; i.e., it expects the tenths of a second in the date and time value. |
Timestamp: "2/25/2009 17:15:23.3"
Mask: "%M/%d/%yyyy %H:%mm:%ss.%f" |
| %ff |
Expects two most significant digits of the seconds fraction;
i.e., it expects the hundredths of a second in the date and time value. |
Timestamp: "2/25/2009 17:15:23.55"
Mask: "%M/%d/%yyyy %H:%mm:%ss.%ff" |
| %fff |
Expects three most significant digits of the seconds fraction;
i.e., it expects the milliseconds in the date and time value. |
Timestamp: 2/25/2009 17:15:23.076
Mask: "%M/%d/%yyyy %H:%mm:%ss.%fff" |
| %t |
Expects the first character of the AM/PM designator.
Designators should match the locale settings: read more... |
Timestamp: "2/25/2009 3:15 P"
Mask: "%M/%d/%yyyy %h:%mm %t" |
| %tt |
Expects the entire AM/PM designator.
Designators should match the locale settings: read more...
|
Timestamp: "2/25/2009 3:15 PM"
Mask: "%M/%d/%yyyy %h:%mm %tt" |
Note: Tokens without leading zeros
The %M, %d, %h, %m and %s tokens must always be followed by a non-digit character; e.g., "/", ":", " ", or must be at the end of the string. Failing to follow this rule may cause incorrect parsing of the date.
Month and Weekday Name Localization
Month Names
If you need to use timestamps with month names instead of month numbers, and the names are not specified in English - you need to define what names are to be used.
To use the textual representation of months names, you need the %MMM or %MMMM token; the first one expects abbreviated month names (e.g. Jan, Feb, etc.), and the second one - full names (e.g. January, February, etc.)
To change month names from English to any other, use the <names> node - for %MMMM, and the <short_names> node - for %MMM. In these nodes, list the new month names from January through December.
This sample XML shows how to change the full and abbreviated names to Czech:
05 |
<names><![CDATA[leden,únor,březen,duben,květen,červen,červenec,srpen,září,říjen,listopad,prosinec]]></names> |
06 |
<short_names><![CDATA[I,II,III,IV,V,VI,VII,VIII,IX,X,XI,XII]]></short_names> |
05 | names: "leden,únor,březen,duben,květen,červen,červenec,srpen,září,říjen,listopad,prosinec", |
06 | shortNames: "I,II,III,IV,V,VI,VII,VIII,IX,X,XI,XII" |
Once these names are set, the parser is able to properly interpret timestamps like: "12-II-2009" or "23-duben-2009"
The advanced explanation accompanied with samples can be found in:
Weekday Names
To use the full or short weekday names, you need the %dddd or %ddd tokens. If these names come in a language other than English, they should be specified in the <names> and <short_names> subnodes of the <week_days> node. The weekday names must be listed from Sunday through Saturday.
The sample XML below shows how to make the parser understand weekday names in Czech:
05 |
<names><![CDATA[neděle,pondělí,úterý,středa,čtvrtek,pátek,sobota]]></names> |
05 | names: "neděle,pondělí,úterý,středa,čtvrtek,pátek,sobota", |
The advanced information accompanied with samples can be found in:
AM/PM Designators
Be default, the %tt token expects the "AM" or "PM" string, and %t - "A" or "P". If you use timestamps in the 12-hour format and use other AM/PM designators, you need to define new designators.
To change the full designators, use the am_string and pm_string attributes for the %tt node, and to change the short designators use the short_am_string and short_pm_string attributes (used in %t) of the <time> node.
Here is a sample XML syntax that demonstrates the use of timestamps with lower-case designators with dots: "5:15 p.m.", "5:15 a.m.":
More samples on using AM/PM designators, accompanied with detailed descriptions, can be found in:
Formatting Samples
This section shows and explains samples of most popular formats. These formats are divided in several section, in each you will find sample format mask, explanation and live samples.
Timestamps with Date
To work with timestamps where day, month and year are shown as numbers you can use the following:
The table below demonstrates a few samples of formatting mask with these tokens:
| Description |
Timestamps |
Timestamp mask format |
| Month and day without leading zero: month, day and year separated with "/". |
1/6/2009
2/27/2009
10/14/2009
12/9/2009
|
"%M/%d/%yyyy" |
| Month and day with leading zero: month, day and year separated with "/". |
01/06/2009
02/27/2009
10/14/2009
12/09/2009 |
"%MM/%dd/%yyyy" |
| Month and day without leading zero: month, day and year separated with "." |
6.1.2009
27.2.2009
14.10.2009
9.12.2009 |
"%d.%M.%yyyy" |
| Month and day with leading zero: month, day and year separated with "." |
06.01.2009
27.02.2009
14.10.2009
09.12.2009
|
"%dd.%MM.%yyyy" |
| Month and day with leading zero: year, month and day separated with "-" |
2009-01-06
2009-02-27
2009-10-14
2009-12-09 |
"%yyyy-%MM-%dd" |
| Month and day with leading zero and year as two numbers, separated with "/" |
01/06/09
02/27/09
10/14/09
12/09/09 |
"%MM/%dd/%yy" |
| Year, month and day with leading zeros without any separators. |
20090106
20090227
20091014
20091209 |
"%yyyy%MM%dd" |
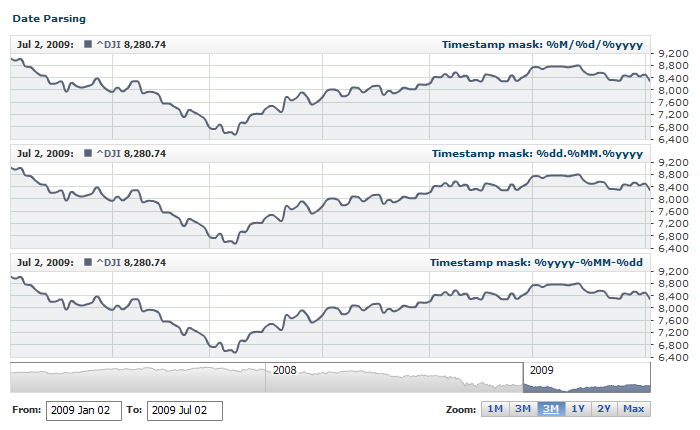
The live sample below shows the same table in three formats with different timestamps: "%M/%d/%yyyy", "%dd.%MM.%yyyy" and "%yyyy-%MM-%dd":
Live Sample: Input Data - Parsing Different Timestamps
Timestamps with Month Names (e.g. 2009-Jan-17)
To use month names instead of month numbers - i.e. timestamps like "5 Jan, 2008" or "5 January, 2008" - your mask formatting string must include the %MMM or %MMMM token.
When these tokens are included in the mask, parser checks the full or abbreviated month names and converts those to the numbers.
Note: Either full or abbreviated month names must strictly match the default or locale-defined values. Using undefined names can result in parsing failure.
Changing short and full months names is described in:
The table below demonstrates a few samples of formatting mask with short and full month names:
| Description |
Timestamps |
Timestamp mask format |
| Dates with short month names |
17 Jan, 2009
17 Feb, 2009
17 Mar, 2009
17 Apr, 2009
17 May, 2009
17 Jun, 2009
17 Jul, 2009
17 Aug, 2009
17 Sep, 2009
17 Oct, 2009
17 Nov, 2009
17 Dec, 2009
|
"%dd %MMM, %yyyy" |
| Dates with full month names |
17 January, 2009
17 February, 2009
17 March, 2009
17 April, 2009
17 May, 2009
17 June, 2009
17 July, 2009
17 August, 2009
17 September, 2009
17 October, 2009
17 November, 2009
17 December, 2009 |
"%dd %MMMM, %yyyy" |
| Dates with short month names + Time |
17 Jan, 2009 4:34:12 AM
17 Feb, 2009 4:34:12 AM
17 Mar, 2009 4:34:12 AM
17 Apr, 2009 4:34:12 AM
17 May, 2009 4:34:12 AM
17 Jun, 2009 4:34:12 AM
17 Jul, 2009 4:34:12 AM
17 Aug, 2009 4:34:12 AM
17 Sep, 2009 4:34:12 AM
17 Oct, 2009 4:34:12 AM
17 Nov, 2009 4:34:12 AM
17 Dec, 2009 4:34:12 AM |
"%dd %MMM, %yyyy %h:%mm:%ss %tt " |
| Dates with full month names + Time |
17 January, 2009 4:34:12 AM
17 February, 2009 4:34:12 AM
17 March, 2009 4:34:12 AM
17 April, 2009 4:34:12 AM
17 May, 2009 4:34:12 AM
17 June, 2009 4:34:12 AM
17 July, 2009 4:34:12 AM
17 August, 2009 4:34:12 AM
17 September, 2009 4:34:12 AM
17 October, 2009 4:34:12 AM
17 November, 2009 4:34:12 AM
17 December, 2009 4:34:12 AM
|
"%dd %MMMM, %yyyy %h:%mm:%ss %tt " |
Here is a live sample with a data set that uses the "%d-%MMMM-%yyyy" formatting mask. The CSV table built into the XML is used for demonstration purposes:
Live Sample: Input Data Sample - Parsing Timestamps with Month Names
Timestamps with Weekday Names (e.g. Monday, 01/27/2009)
When you need to use a timestamp with a weekday name (which is not recommended though), like "Sunday, 5/15/2009", you can use the %ddd or %dddd tokens. The first one expects the abbreviated, and the second one - full weekday name. Please note that weekday name doesn't affect the date calculation at all.
Please use these tokens only when you have to use timestamps with weekday names; if you can create timestamps without the names - do that, because that improves the performance greatly.
Note: By default, the parser understands only English weekday names, if you need to parse weekday names in other languages, you need to redefine those in the locale settings.
To learn more about localizing weekday names, please see:
The table below demonstrates a few variants with weekday names in the formatting mask:
| Description |
Timestamps |
Timestamp mask format |
| Shortened weekday at the beginning. |
Mon, 29 March 2010
Tue, 30 March 2010
Wed, 31 March 2010
Thu, 1 April 2010
Fri, 2 April 2010
Sat, 3 April 2010
Sun, 4 April 2010 |
"%ddd, %d %MMMM %yyyy" |
| Full weekday at the beginning. |
Monday, 29 March 2010
Tuesday, 30 March 2010
Wednesday, 31 March 2010
Thursday, 1 April 2010
Friday, 2 April 2010
Saturday, 3 April 2010
Sunday, 4 April 2010 |
"%dddd, %d %MMMM %yyyy" |
| Weekday as part of timestamp. |
29 March - Monday, 2010
30 March - Tuesday, 2010
31 March - Wednesday, 2010
1 April - Thursday, 2010
2 April - Friday, 2010
3 April - Saturday, 2010
4 April - Sunday, 2010 |
"%d %MMMM - %dddd, %yyyy" |
This live sample demonstrates data set with timestamps that contain weekday names:
Live Sample: Input Data - Parsing Timestamps with Days of Week
12-hour time format (e.g. 5:35:30 PM)
The 12-hour clock is a time conversion convention, in which the 24 hours of the day are divided into two periods called ante meridiem (a.m., Latin: "before mid day" English: "before noon") and post meridiem (p.m., Latin: "after mid day" English: "after noon"). Each period consists of 12 hours, numbered as 12 (acting as zero), 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, and 11.
A good starting point to learn more about this format is:
These are tokens that can be used for parsing timestamps in the 12-hour format:
Note: If you use the 12-hour time format, you must use the %t or %tt tokens in the format string and the AM/PM designators in timestamps. If the designator format is different from the default, you can change it. Changing designators is described in:
The table below demonstrates different variations of formatting masks along with sample timestamps:
| Description |
Timestamps |
Timestamp mask format |
| Hours |
12/6/2009 3 AM
12/6/2009 5 PM
12/6/2009 11 PM
12/6/2009 6 AM
|
"%M/%d/%yyyy %h %tt" |
| Hours + Minutes |
12/6/2009 3:15 AM
12/6/2009 5:32 PM
12/6/2009 11:10 PM
12/6/2009 6:45 AM |
"%M/%d/%yyyy %h:%mm %tt" |
| Hours + Minutes + Seconds |
12/6/2009 3:15:10 AM
12/6/2009 5:32:27 PM
12/6/2009 11:10:18 PM
12/6/2009 6:45:14 AM |
"%M/%d/%yyyy %h:%mm:%ss %tt" |
| Hours(with leading zero) |
12/6/2009 03 AM
12/6/2009 05 PM
12/6/2009 11 PM
12/6/2009 06 AM
|
"%M/%d/%yyyy %hh %tt" |
| Hours(with leading zero) + Minutes |
12/6/2009 03:15 AM
12/6/2009 05:32 PM
12/6/2009 11:10 PM
12/6/2009 06:45 AM |
"%M/%d/%yyyy %hh:%mm %tt" |
| Hours(with leading zero) + Minutes + Seconds |
12/6/2009 03:15:10 AM
12/6/2009 05:32:27 PM
12/6/2009 11:10:18 PM
12/6/2009 06:45:14 AM |
"%M/%d/%yyyy %hh:%mm:%ss %tt" |
If your data set shows data within a day, you can use the Base Date method to make the data set smaller. Learn more about that in:
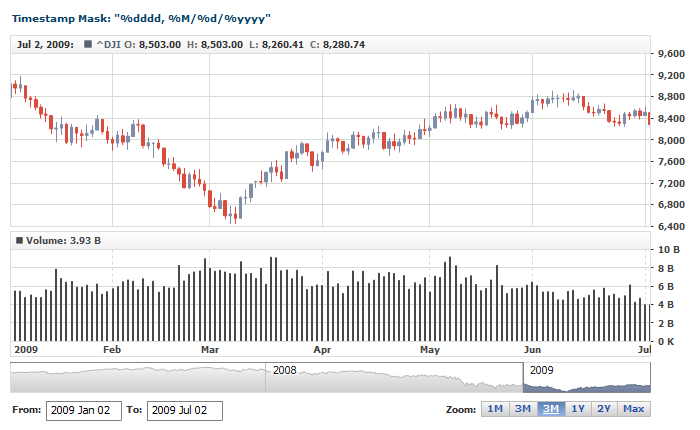
Here is a live sample with a data set that uses the "%M/%d/%yyyy %h:%mm:%ss %tt" formatting. The data set built into the XML is used for demonstration purposes:
Live Sample: Input Data Sample - Parsing Timestamps with 12 Hours Format
24-hour time format (e.g. 17:35:30)
The 24-hour clock is a convention of time keeping, in which a day runs from midnight to midnight and is divided into 24 hours, indicated by the hours passed since midnight, from 0 to 23. This time notation system is the world's most commonly used one.
You can learn more about the 24-hour format in:
The following tokens are used for the 24-hour format:
- 24-hour time format-specific tokens: %H, %HH
- General time tokens : %m, %mm, %s, %ss
The table below demonstrates a few variations of formatting masks along with 24-hour format timestamps:
| Description |
Timestamps |
Timestamp mask format |
| Hours |
23.12.2009 0
23.12.2009 17
23.12.2009 23
23.12.2009 4
|
"%MM.%dd.%yyyy %H" |
| Hours + Minutes |
23.12.2009 15:23
23.12.2009 17:32
23.12.2009 11:10
23.12.2009 6:45 |
"%MM.%dd.%yyyy %H:%mm" |
| Hours + Minutes + Seconds |
23.12.2009 3:15:10
23.12.2009 17:32:27
23.12.2009 11:10:18
23.12.2009 6:45:14 |
"%MM.%dd.%yyyy %H:%mm:%ss" |
| Hours(with leading zero) |
23.12.2009 00
23.12.2009 17
23.12.2009 23
23.12.2009 04
|
"%MM.%dd.%yyyy %HH" |
| Hours(with leading zero) + Minutes |
23.12.2009 15:23
23.12.2009 17:32
23.12.2009 11:10
23.12.2009 06:45 |
"%MM.%dd.%yyyy %HH:%mm" |
| Hours(with leading zero) + Minutes + Seconds |
23.12.2009 03:15:10
23.12.2009 17:32:27
23.12.2009 11:10:18
23.12.2009 06:45:14 |
"%MM.%dd.%yyyy %HH:%mm:%ss" |
The live sample below shows a data set with the "%dd.%MM.%yyyy %HH:%mm:%ss" formatting mask. The data set built into the XML is used for demonstration purposes:
Live Sample: Input Data Sample - Parsing Timestamps with 24 Hours Format
Unix Timestamps
Unix timestamp is a way of tracking time as a running total of seconds. This count starts at the Unix Epoch on January 1st, 1970. Therefore, unix timestamp is merely the number of seconds between a particular date and the Unix Epoch. This is very useful to computer systems for tracking and sorting dated data in dynamic and distributed applications, both online and client-side.
A good starting point to learn more about Unix Timestamp is:
The table below shows what timestamps of this format look like:
| Timestamps |
Timestamp format string |
|
1269680933
1269681053
1269681353
1269681653
1269681953 |
%u |
Here is a sample XML for making the parser understand timestamps in this format:
01 |
<?xml version="1.0" encoding="UTF-8"?> |
02 |
<stock xmlns="http://anychart.com/products/stock/schemas/1.9.0/schema.xsd"> |
18 | csvData: "915570000,24.4\r\n915656400,25.73\r\n916002000,25.89\r\n916088400,26.71\r\n916174800,25.95\r\n916261200,25.24\r\n916347600,25\r\n916434000,25.63\r\n916693200,25.89" |
The live sample below shows a chart with the timestamps in the CSV table are Unix timestamps. For demonstration purposes, we will use the CSV table built into the XML:
Live Sample: Input Data Sample - Parsing Timestamps with Unix Time
Timestamps in Milliseconds
You have two ways to use timestamps at a millisecond precision:
- Milliseconds - you can use the "Milliseconds since midnight January 1, 1970" format using the %T format. This format is the preferred one, for it is shorter than "23.12.2009 23:15:10.959" and is parsed very efficiently.
- Complex String - regular time format with the %f, %ff, and %fff tokens.
The table below demonstrates different variants of timestamps and masks with milliseconds:
| Description |
Timestamps |
Timestamp mask format |
| Milliseconds since midnight January 1, 1970 |
1269689056645
1269689056768
1269689056891
1269689057014
|
"%T" |
| Tens of milliseconds |
23.12.2009 23:15:10.2
23.12.2009 23:15:10.5
23.12.2009 23:15:10.2
23.12.2009 23:15:10.9 |
"%MM.%dd.%yyyy %H:%mm:%ss.%f" |
| Hundreds of milliseconds |
23.12.2009 23:15:10.21
23.12.2009 23:15:10.58
23.12.2009 23:15:10.04
23.12.2009 23:15:10.95 |
"%MM.%dd.%yyyy %H:%mm:%ss.%ff" |
| Milliseconds |
23.12.2009 23:15:10.218
23.12.2009 23:15:10.581
23.12.2009 23:15:10.047
23.12.2009 23:15:10.959
|
"%MM.%dd.%yyyy %H:%mm:%ss.%fff" |
If you use complex timestamps like "23.12.2009 23:15:10.047", you can make them shorter using the Base Date method. This method is described in:
The live sample below demonstrates using several CSV tables with different timestamps:
Live Sample: Input Data Sample - Parsing Timestamps in Milliseconds
Using Base Date to Shorten Timestamps
To explain what Base Date is, and how you can make use of it, we will give you a little explanation of how the parser engine creates the internal representation of timestamps:
- When the parser reads a row in the CSV table, it creates a template Base Date value; by default that is "1970-01-01 00:00:00.000".
- Then it reads the timestamp and gets the time units from it according to the format mask. When a unit is parsed, it is inserted into the base date template.
Thus, if you give the parser only "May, 20" - it will become"1970-05-20 00:00:00.000"
AnyChart Stock gives you the ability to alter Base Date using the base_date attribute of the <date_time> node; the date can be set according to the rules described in Input Date-Time Format.
The ability to set Base Date helps to avoid redundancy in timestamps; see sample XML below - it contains data with a millisecond precision and to avoid redundancy uses the base_date value:
16 | csvData: "044,244.4\r\n046,231.73\r\n048,178.89\r\n052,287.71\r\n054,145.95\r\n056,198.24\r\n058,170.12\r\n060,164.63\r\n062,211.89" |
As you can see here, the use of this method allows making data sets much smaller, and, moreover, parsing much faster. These two facts allow to gain a great improvement in the performance.
The table below shows a sample use of the Base Date method. The first column contains the formatting mask, description and base date; second column - timestamp as it could be set in the data set; and the third column - the resulting values that would be created by the parser and used for drawing the chart:
| Description |
Timestamp |
Result Timestamp |
| 24-hour intraday time.
Mask: "%HH:%mm"
Base Date: |
01:00 |
01:00:00.000 |
| 13:45 |
13:45:00.000 |
| 16:55 |
16:55:00.000 |
| 23:34 |
23:34:00.000 |
| 12-hour formatted time.
Mask: "%h:%mm %tt"
Base Date: |
1:00 AM |
01:00:00.000 |
| 1:45 PM |
13:45:00.000 |
| 4:55 PM |
16:55:00.000 |
| 11:34 PM |
23:34:00.000 |
| Minutes and second within one hour.
Mask: "%mm:%ss"
Base Date: |
00:00 |
00:00.000 |
| 10:30 |
10:30.000 |
| 15:20 |
15:20.000 |
| 59:30 |
59:30.000 |
| Millisecond precision within one hour.
Mask: "%mm:%ss.%fff"
Base Date: |
00:00.031 |
00:00.031 |
| 10:30.581 |
10:30.581 |
| 15:20.322 |
15:20.322 |
| 59:30.999 |
59:30.999 |
| Millisecond precision within one hour.
Mask: "%mm:%ss.%fff"
Base Date: |
00:00.031 |
1970-01-01 00:00:00.031 |
| 10:30.581 |
1970-01-01 00:10:30.581 |
| 15:20.322 |
1970-01-01 00:15:20.322 |
| 59:30.999 |
1970-01-01 00:59:30.999 |
| Year only.
Mask: "%yyyy"
Base Date: |
1991 |
1991-01-01 00:00:00.000 |
| 1992 |
1992-01-01 00:00:00.000 |
| 1993 |
1993-01-01 00:00:00.000 |
| 1994 |
1994-01-01 00:00:00.000 |
| Month and year only.
Mask: "%MM/%yyyy"
Base Date: |
12/1991 |
1991-12-01 00:00:00.000 |
| 01/1992 |
1992-01-01 00:00:00.000 |
| 02/1992 |
1992-02-01 00:00:00.000 |
| 03/1992 |
1992-03-01 00:00:00.000 |
The live sample below uses data set that uses base date:
Live Sample: Input Data Sample - Using Base Timestamp
Note: When adding points using appendData(), the base date and formatting mask must too be taken into account.
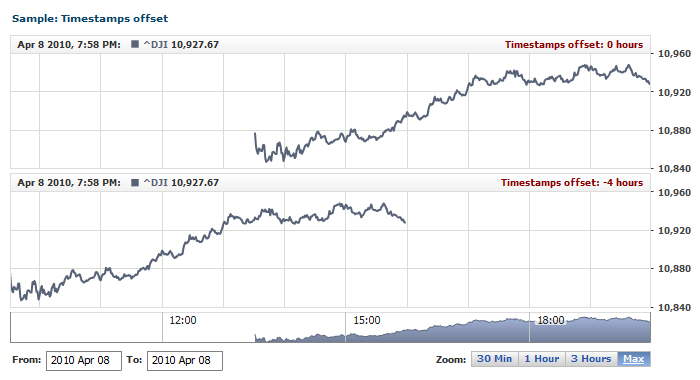
Timestamp Offset
When defining a data set, you can set timestamps offset specified in hours. This may be useful when the data is created in one time zone and then viewed in a different one.
For example, suppose there is a server broadcasting a live feed from Hong Kong Stock Exchange (HKEX), where the trading hours are specified for the China time zone; if a viewer from Paris sees the chart created with AnyChart Stock based on the original values, he would see the 6-hour offset from his local time. With the time offset configured, the same user would see the same chart, now with his local time on it.
You can set time offset on the server side, by making modifications in the initial data set, but using AnyChart Stock's built-in time offset setting can make the server-side script lighter, shifting the load to clients.
To set time offset, use the offset attribute in the <date_time> node; it accepts values in hours, which can be positive, negative or fractional.
The sample XML below shows how to set a +6.5-hours offset:
08 |
<csv_data><![CDATA[4/8/2010 1:32:00 PM,10857.8398 |
09 |
4/8/2010 1:33:00 PM,10854.9697 |
10 |
4/8/2010 1:34:00 PM,10860.4102 |
11 |
4/8/2010 1:35:00 PM,10859.7305 |
12 |
4/8/2010 1:36:00 PM,10858.8203 |
13 |
4/8/2010 1:37:00 PM,10857.9199]]></csv_data> |
08 | format: "%M/%d/%yyyy %h:%mm:%ss %tt" |
16 | csvData: "4/8/2010 1:32:00 PM,10857.8398\r\n4/8/2010 1:33:00 PM,10854.9697\r\n4/8/2010 1:34:00 PM,10860.4102\r\n4/8/2010 1:35:00 PM,10859.7305\r\n4/8/2010 1:36:00 PM,10858.8203\r\n4/8/2010 1:37:00 PM,10857.9199" |
The live sample below demonstrates how several data sets can use the same CSV table for different charts. One chart could show data according to the original timestamps, and the other one - with the -4.0 hours (four hours back) offset:
Live Sample: Input Data Sample - Settings Timestamps Offset
Note: If on your chart you use Event Markers, and they are bound to a series that shows offset values, the offset must be used in the Event Markers as well. You can learn how to do that for Event Markers in Event Markers: Timestamp Offset.
Number Format
Decimal and thousand separators vary from country to country; to use values in a local standard, you need to use the decimal_separator and thousands_separator attributes of the <number> node to define custom separators.
Here is a sample XML configuration that shows how to make the parser understand values like "23,8712", where comma (",") is used as the decimal separator:
09 |
<csv_data><![CDATA[Date,Open,High,Low,Close |
10 |
2009-10-01,"10'877,26","10'896,99","10'877,26","10'896,99" |
11 |
2009-10-02,"10'863,51","10'876,73","10'862,83","10'876,73" |
12 |
2009-10-03,"10'857,84","10'863,21","10'857,84","10'863,21" |
13 |
2009-10-04,"10'854,97","10'858,82","10'852,93","10'857,92" |
14 |
2009-10-05,"10'860,41","10'860,41","10'854,29","10'855,35" |
15 |
2009-10-06,"10'859,73","10'861,62","10'858,82","10'861,09" |
16 |
2009-10-07,"10'858,82","10'863,58","10'858,37","10'859,65" |
17 |
2009-10-08,"10'857,92","10'860,94","10'857,92","10'858,52" |
18 |
2009-10-09,"10'863,28","10'863,96","10'857,99","10'858,22"]]></csv_data> |
19 | csvData: "Date,Open,High,Low,Close\r\n2009-10-01,\"10'877,26\",\"10'896,99\",\"10'877,26\",\"10'896,99\"\r\n2009-10-02,\"10'863,51\",\"10'876,73\",\"10'862,83\",\"10'876,73\"\r\n2009-10-03,\"10'857,84\",\"10'863,21\",\"10'857,84\",\"10'863,21\"\r\n2009-10-04,\"10'854,97\",\"10'858,82\",\"10'852,93\",\"10'857,92\"\r\n2009-10-05,\"10'860,41\",\"10'860,41\",\"10'854,29\",\"10'855,35\"\r\n2009-10-06,\"10'859,73\",\"10'861,62\",\"10'858,82\",\"10'861,09\"\r\n2009-10-07,\"10'858,82\",\"10'863,58\",\"10'858,37\",\"10'859,65\"\r\n2009-10-08,\"10'857,92\",\"10'860,94\",\"10'857,92\",\"10'858,52\"\r\n2009-10-09,\"10'863,28\",\"10'863,96\",\"10'857,99\",\"10'858,22\"" |
Note: If you have to use comma (",") for the decimal or thousand separator, and you cannot avoid this, you must enclose the values in double quotes. Learn more about this in the CSV Settings and CSV Table Requirements section.
The live sample below demonstrates how a custom number formatting in data set can be implemented with AnyChart Stock:
Live Sample: Input Data Sample - Settings Number Format
Performance Improvement Recommendations
If you have the full control over your data source and can create those in any format, please consider the recommendations of this section; they will help you to improve the component's and application's performance.
1. Table Size
A CSV table can contain thousands of rows, and it may be useful to analyze it and check whether it is redundant. Each cell with a timestamp or value may contain unnecessary information, which is not actually required.
Data redundancy may cause the following problems:
- Bandwidth Overload - AnyChart Stock is a client-side component; it renders charts on the client side. So, to display a chart, the component needs to get the data table from the server. Besides, every time user wants to see new data, a new chunk of data is to be transferred from server to client. The CSV format is pretty compact, but large data sets can cause bandwidth overload if user has a low-capacity Internet channel.
- Low Parsing Performance - the more characters you have in the value fields and the more complex format your timestamps have, the more operations parser needs to carry out. It is recommended to use simple timestamps and add only necessary data fields to the table.
Table Size Reduction Recommendations:
- Avoid redundant timestamp formats - shorter timestamps is a better choice, and standard formats are better than complex ones. If you display data with a minute or second precision, it is better to use Unix Timestamp and the %u token rather than "%yyyy-%M-%d %h:%mm:%ss.%fff %tt". If you work with milliseconds - use the %T token and format.
Also, it may happen that a timestamp looks like:"Date: 1/5/1999" - where the repeating "Date: " string has no additional information and merely expands the table and slows down parsing.
- Add only necessary data fields - if you aren't going to use some of the data fields - do not add them to the data set. For example, if you are going to chart only the closing price, obviously, there is no need to add the opening price to the table.
- Avoid value redundancy - for example, decimal digits; if you are going to chart and display only two decimal digits in the tooltips, there is no need to pass values like "15.128271620321" to the component - it is much better to round the values on the server side and then pass "15.13".
- Do not use thousand separators - separators are needed only for purpose of displaying, and you can make the display settings in the component. By using values like "5,000,000,000.23" in your CSV table you merely slow down the parsing.
- Do not use leading zeros in values - leading zeros in values (unlike leading zeros in dates) are not a good choice. Say, "0000000002.23" is mathematically identical and equal to "2.23", but the latter is shorter and is parsed much faster.
- Use Compression - if the bandwidth is limited, compress your CSV tables on the server-side; although that gives a bit of extra load to the server and slows parsing time a bit, the bandwidth is used more efficiently. You can learn about the compression pros and cons in the Data Compression article.
- Use base date to shorten timestamps - this method allows creating very compact data sets. Learn more about it in Using Base Date to shorten Timestamps.
2. Parsing Speed
A CSV table parsing speed depends on many factors, and this section highlights the most significant of those. Please go through this checklist if you happen to be dissatisfied with the performance of the component or your application.
Not recommended:
- 12-hour time format: the parser converts this format to the 24-hour one anyway, and that requires more parsing time.
- Tokens without leading zeros: %M, %d, %h, %m and %s - parsing these tokens requires additional checks.
- Textual month and weekdays: %ddd, %dddd, %MMM and %MMMM - the use of these token slows the parser down tremendously, as it must check each name against the corresponding list.
- Custom decimal separators in values - do not use custom decimal separators: "1562,02132" is parsed slower than "1562.02132" because the dot is a native separator for the Flash Player engine.
- Thousand separator in values - if possible - do not use a thousand separator because the parser needs to remove all the separators when parsing the values.
- Multi character row and column separators in CSV table - the longer separator is used, the more time is spent on parsing the table. The standard comma (",") and CR LF ("\r\n") are your best choice.
Recommended:
- %u token - if you are going to show data with the second or minute precision, the best choice would be using timestamps in the Unix Timestamp format. The string with such timestamp is shorter than the regular date representation, and therefore the parser's performance is essentially better.
- %T token - the most flexible and universal format, and, moreover that's the Flash Player's native timestamp format, so - it is parsed with the best efficiency. If it doesn't add much string length redundancy, use it to speed everything up.
This chart shows the comparison of processing speeds for different timestamps - the bar names are timestamps formatting strings and samples, and the bar length is the processing time (in milliseconds) for 50.000 timestamps in the respective format:
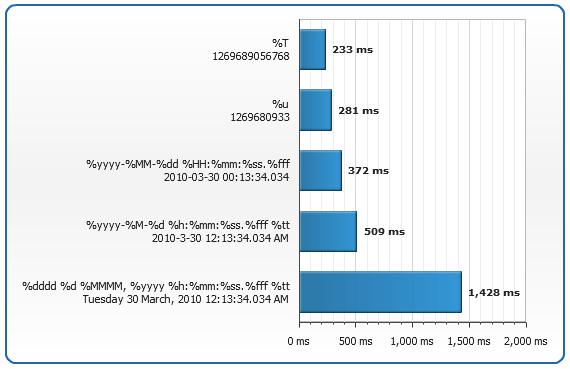
This test has been performed on a PC with the following specifications:
- Processor: Intel(R) Core(TM) Duo CPU E7300 @ 2.66GHz
- Memory (RAM): 4.00 GB
- OS: Windows 7 (32-bit)
- Web Browser: Internet Explorer 8
- Flash Player Version: 10,0,45,2